$ kubectl describe ingress my_ingress -n my_namespace
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedDeployModel 3m41s ingress Failed deploy model due to AccessDenied: User: arn:aws:sts::110111011101:assumed-role/myEKSLoadBalancerControllerRole/1234561234561234561 is not authorized to perform: elasticloadbalancing:AddTags on ause no identity-based policy allows the elasticloadbalancing:AddTags action
구글에서는 위 에러 메시지와 관련된 내용은 찾기 어려웠다. AWS 문서 뒤적이며 loadBalancerController 생성하는 부분을 찾아보니, iam_policy.json 파일이 v2.3.0 에서 v.2.5.4 로 업데이트 되어 있었고, 아래 정책이 추가된 것을 확인했다.
2023년 2월 15일부터 Amazon EKS는 Kubernetes 1.21 버전을 더 이상 지원하지 않습니다. 또한 그 이후, 더 이상 새 1.21버전의 클러스터를 생성할 수 없으며 Kubernetes 1.21 버전을 사용중인 모든 EKS 클러스터는 최신 플랫폼 버전의 Kubernetes 버전 1.22로 업데이트될 예정입니다. ... 1.21 버전의 클러스터를 Kubernetes 1.22 버전 이상으로 업데이트하는 것을 권장드립니다. 클러스터를 바로 가장 최신 Kubernetes 버전인 1.24 버전으로 업데이트하여, 버전 업데이트를 수행해야 하는 빈도를 최소화할 수 있습니다.
일단 EKS 버전 업데이트가 처음인데다가, 현재 운영중인 클러스터라 다운타임이 발생하면 회사에 치명적, 내 수명에도 치명적... 다른일 처리하다가 미루고 미루다 보니 내일 모레가 듀 데이트... 다행히 개발/운영 클러스터를 각각 사용하고 있어서 개발 클러스터로 다운타임이 발생하지 않는지 확인할 수 있었다. 결론부터 말하면 fargate 사용시 다운타임은 발생하지 않았다.
이왕 손댔을 때, 메일에 쓰인대로 1.21 버전에서 1.24 버전으로 올리면 좋겠지만 한번에 하나의 마이너버전 업데이트만 가능하다. 일단 업데이트 전 버전별 업데이트 주의사항들을 확인해 봤다.
이 정도인 것 같다. kubectl 은 로컬에 lens, docker 등에서도 설치가 되어 최신버전이 표시되게 설정이 필요하다. kubectl 버전은 EKS 클러스터 API 버전을 기준으로 마이너버전 +-1 만 사용이 가능하다. 예를 들어 1.23 kubectl Client 는 Kubernetes 1.22, 1.23, 1.24 클러스터에서 사용이 가능하다... 고는 하는데, kubectl client 1.24 과 server 1.21 을 사용할 때 큰 이슈는 없었다... 아무튼 최신버전(1.25+)에서는 제약이 있는 듯. yaml 파일 수정은 rbac.authorization.k8s.io/v1beta1 하나 했고, ALB Controller 는 업데이트 하지 않았더니 무한 restart...ㅎ
업데이트시, 충돌 옵션을 선택하지 않으면 아래와 같은 에러가 발생한다. 옵션에서 [재정의] 를 선택하면 된다.
Conflicts found when trying to apply. Will not continue due to resolve conflicts mode. Conflicts: ConfigMap kube-proxy-config - .data.config DaemonSet.apps kube-proxy - .spec.template.spec.containers[name="kube-proxy"].image DaemonSet.apps kube-proxy - .spec.template.spec.containers[name="kube-proxy"].image
EBS CSI driver 가 정상적인 권한으로 설치되지 않으면 Volumes mount 가 실패하고 에러가 발생한다.
failed to provision volume with StorageClass "gp2": rpc error: code = Internal desc = Could not create volume "pvc-c1234a61-1234-4321-1234-12347d4f1234": could not create volume in EC2: NoCredentialProviders: no valid providers in chain caused by: EnvAccessKeyNotFound: failed to find credentials in the environment. SharedCredsLoad: failed to load profile, . EC2RoleRequestError: no EC2 instance role found caused by: RequestError: send request failed caused by: Get "http://111.111.111.111/latest/meta-data/iam/security-credentials/": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
EKS v1.24 업데이트
v1.24 에서는 따로 설정을 변경한 것은 없었지만, PSP(PodSecurityPolicy) 가 v1.25에서는 제거될 예정이라 PSS(PodSecurityStandards) 로 대체할 수 있다. PSS 설치 내용이 너무 길어서; v1.25 언제 쓸지도 모르는데 일단 그때까지 보류하는걸로
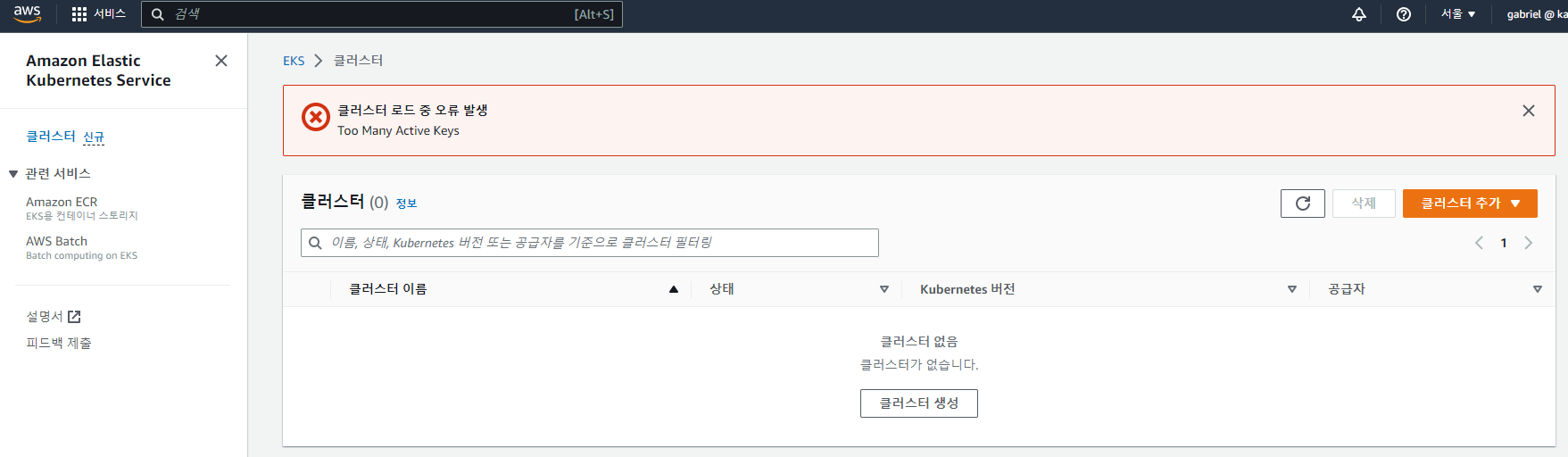
$ aws eks update-kubeconfig --region ap-northeast-2 --name my-cluster --profile my-profile
An error occurred (TooManyActiveKeysException) when calling the DescribeCluster operation: Too Many Active Keys
AWS EKS 배포 전에 클러스터 선택하는 첫번째 명령에서 생전 처음보는 에러가... 뭔 ActiveKey 를 얘기하는겨. 아무리 구글을 봐도 관련된 내용이 없네. aws 명령에서 나오는 에러같기는 한데... 내가 뭐 잘못 건드린게 있나. 어제 퇴근전까지만 해도 잘됐는데, 다시 출근하니까 안되네.
AWS 대시보드에 접속해 봤더니...
내 클러스터 다 어디갔슴? 후덜덜 하면서, 다른 계정도 봤더니 다행히 같은 에러. 아무래도 AWS 장애임을 예상하고, 파트너사에 문의해 봤더니, 공동체 중에 EKS 사용하는데가 우리밖에 없다는... 아무튼 서울리전 장애를 확인했고...
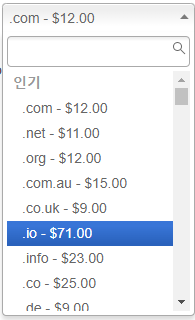
얼마전 도메인이 세개 정도 필요해서 간만에 쇼핑 좀 했다. example.com / example.net 나머지 하나는 뭘로 선택할까... 하다가 구글 검색에 자주 보이는 io 도메인으로 결정했다. 대충 뭐 IT 기술 관련 도메인으로 많이 사용하는 줄로 알고 있긴 했는데 가격이...
AWS 기준으로 닷컴이 $12 인데 io 도메인이 $71 라니... 구글이 $60 로 나오는데 그렇다 해도 .com 의 5배.
어이가 좀 없긴 했는데 궁금하기도 하여 검색을 좀 해봤다.
.io 도메인은 기술기반 스타트업들이나 블록체인 프로젝트에 많이 사용한다. 원래 영국령 인도양식민지(British Indian Ocean Territory)의 국가코드 톱 레벨 도메인으로 한국의 .kr 도메인과 같지만 .io 도메인은 국가 제한이 없는 누구나 사용이 가능할 수 있는 도메인 중 하나이다. 데이터 입출력을 뜻하는 Input/Output 으로도 해석하며 IT 기술기반 업계에서 많이 쓴다고 하는데 그냥 갖다 붙인 느낌... 어쨌든 한참을 그런 업계에서 애용하고 있다니 원한다면 .io 든 .dev 든 사면 되겠지만 가격이 왜 이 모양인지... 비싼 이유를 좀 찾아보려 했으나 해당 글도 별로 없는거 같고 찾고 싶지도 않아졌음. 보아하니 유행 살짝 타니까 돈 좀 벌어볼라고 세계적으로 가격단합 중인거 같은데... 비쌀땐 안사면 됨. 도메인은 .com 이 짱이지...ㅋ
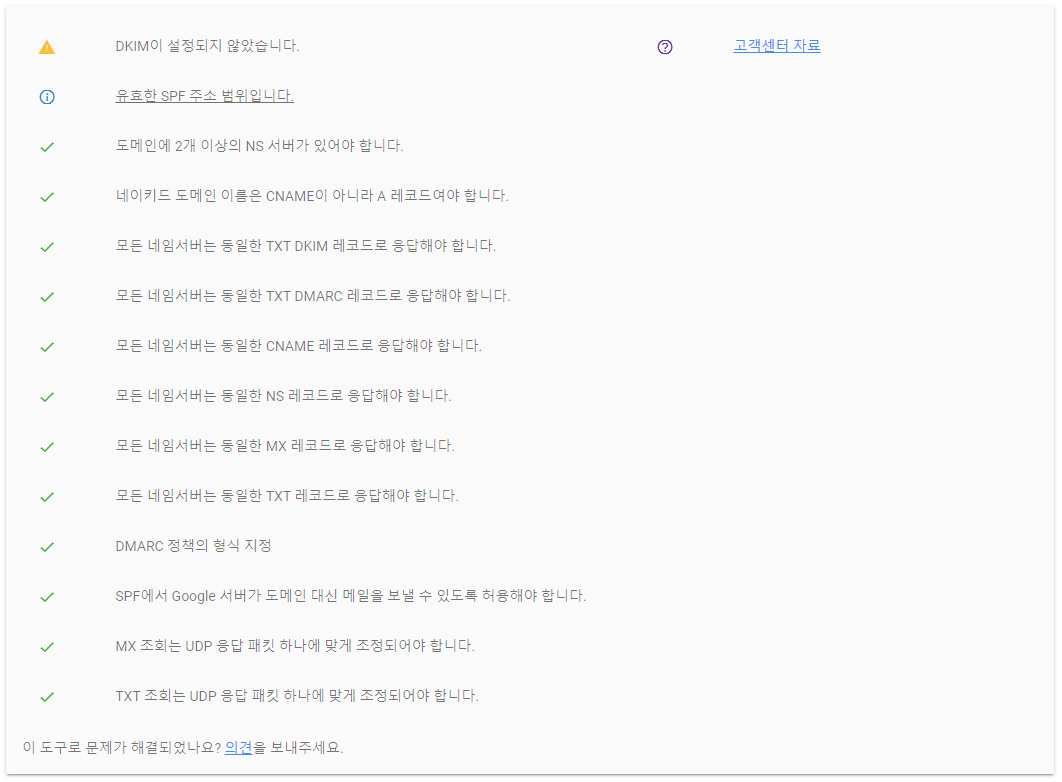
* 요점 대부분의 메일 공급자에서는 SPF레코드가 2014년 4월에 더 이상 사용되지 않으므로 SPF 구성이 적용되지 않습니다. 자세한 내용은 Internet Engineering Task Force(IETF) 웹 사이트에서 RFC 7208을 참조하십시오. SPF 레코드 대신 적용 가능한 값이 포함된 TXT레코드를 만드는 것이 좋습니다.
해결
TXT "v=spf1 include:_spf.google.com ~all"
레코드 유형을 TXT 로 추가하여 해결...
Received-SPF: pass (kakao.com: domain of gabriel@example.com designates 123.123.123.123 as permitted sender)
하는 김에 DMARC 설정 추가하고, DKIM 은 관리자 권한 있으면 추가, 그리고 테스트 ㄱㄱ
또 하나,,, 테스트 한답시고 test1, test2, test3 이 따위로 메일 반복해서 보내면,
Delivery failed: gabriel@kakao.com 10.61.236.127 failed after I sent the message. Remote host said[Response Message]: 554 5.7.1 DAS41 209.85.210.193: Your mail is blocked automatically by anti-spam system. (E04) STEP: DATA SEND