kubernetes 를 사용하면서 불편했던 점 중에 하나는 서비스 로깅이었다. 로컬에서 가장 자주 사용하던 명령어가 바로...
> kubectl logs -n namespace -f <pod-name>
배포(deployment) 하고 나서 로깅/디버깅을 위해 pod 리스트를 나열하고 pod-name 으로 로깅하는 짓이 가장 번거로웠다. 지금은 pod 가 한 10개 정도인데... 창을 10개를 띄워놓을 수도 없고... 그래서 실시간으로 pods 정보를 보여주고, 해당 로그를 스트리밍으로 좀 더 편하게 볼 수 있는 툴을 찾아보기로 했다.
쿠버네티스 모니터링 도구를 찾아보니 꽤나 많이 보이는데 그 중에 몇 가지만 테스트해 보았다.
Kubernetes Dashboard 심플하다. 시스템 모니터는 다른 모든 툴들도 기본적으로 잘 동작한다. CPU / RAM / Workload 등... 하지만 서비스 로깅이 불편하다. 5초 reload 방식... 이것도 대부분의 툴들이 마찬가지.
Prometheus / Grafana 설치 개복잡. Helm 을 사용하면 조금 편함. 잘나가다가 promtail 설정에서 막혔음. Fargate 사용 유저는 엄청난 고뇌가 필요할 듯... 몇가지 대안은 있었지만 로그 하나 보겠다고 굳이 일 벌리고 싶지 않았음. 가장 보편적이기도 하고, Custom / 확장도 좋은 것 같고... 대부분의 회사들이 사용하니 이건 써봐야겠지?
Datadog 시스템 통합으로 사용하고는 있으나... 쿠버네티스에 특화되어 있다기 보다는 로깅 분석에 어울리는... 그렇다고 안되는 건 없는... 그렇다고 굳이 유료 결제할 필요도 없는...?
Lens (Desktop) Kubernetes IDE 답게 쿠버네티스에 특화되어 있음. 얼핏보면 외관은 Prometheus 와 흡사. 클릭 몇번으로 설치 완료. Attach Pod / logs 메뉴로 실시간 로깅은 잘됨. 혼자쓰기 괜츈.
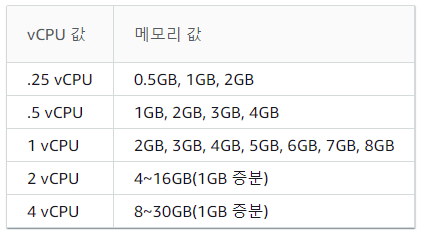
EKS Fargate 를 기본사양으로 약 1달 정도 사용해 봤다. Fargate 의 기본사양(최소사양)은 vCPU 0.25 / memory 0.5GB 이다. 1개의 CPU 코어가 2 vCPU 니까 0.25면... Spring Jar 파일 돌리는데 부팅시 스프링 로그가 2초에 1줄 정도씩 나왔나. 당연히 부팅시간도 상당히 늘어난다. ALB 의 health check 도 길어지고... 부팅된 후에는 Lazy 설정 때문에 Slave DataSource 가 처음 세팅될 때도 10초 이상의 응답으로 Timeout 이 발생하기도 했다. 그것 빼고는 단일 어플리케이션 돌아가는데 큰 문제는 없어보였다. 이것저것 다 빼다보면 어디다 써야할지... t2.nano 보다도 낮은 사양... 우선 xms / xmx 을 확인해 봤다.
EKS 에서 ingress 와 loadbalancer 를 생성했는데 pending 상태라 살펴보니 자격증명 실패 에러가 발생했다.
$ kubectl describe ingress my-ingress
Warning FailedBuildModel 32m (x9 over 47m) ingress (combined from similar events): Failed build model due to WebIdentityErr: failed to retrieve credentials
caused by: InvalidIdentityToken: Incorrect token audience
status code: 400, request id: 4599a6da-7a29-4d82-baf7-d546e7811234
확인하고 삭제하려는데 삭제가 안된다.ㅋ 강제 삭제(--force --grace-period=0)도 안된다; 시간이 한참 지나도 프롬프트가 멈춰버림.
$ kubectl describe svc my-nlb
...
Normal DeletedLoadBalancer 40m service-controller Deleted load balancer
Warning FailedDeployModel 38m service Failed deploy model due to WebIdentityErr: failed to retrieve credentials
Warning ClusterIPNotAllocated 75s (x5 over 37m) ipallocator-repair-controller Cluster IP [IPv4]:172.20.23.140 is not allocated; repairing
Warning PortNotAllocated 75s (x5 over 37m) portallocator-repair-controller Port 32083 is not allocated; repairing
권한은 없는데 복구 의지가 강해서 그런건지, 안죽고 계속 살아나려고 발버둥 치는 느낌. 다른 서비스들과 결합이 되어 있는건지... 클러스터를 거의 초기화 수준으로 다른 모든 리소스를 다 지웠는데도 삭제가 안되는 생명줄 긴 로드 밸런서들. 구글님 덕에 겨우 찾아 삭제했다.
finalizers 는 리소스를 완전히 삭제하기 전에 특정 조건이 충족될 때까지 대기하게 한다. 삭제가 완료되면 대상에서 관련 finalizers 를 삭제하는데, 위처럼 metadata.finalizers 필드를 비워주면 Kubernetes 는 삭제가 완료된 것으로 인식하게 된다.
ALB 생성 역시 NLB 와 흡사하지만 ingress 리소스를 생성해야 하고, NodePort 나 LoadBalancer 타입의 Service 를 생성하는 것이 다르다. 마찬가지로 nginx 의 첫화면을 확인하는 샘플. 어플리케이션 배포는 NLB 테스트에 사용한 것과 동일, ALB / NodePort 정상 구동 확인하고, 브라우저에서 nginx 확인하고...
1. Sample namespace
$ kubectl create namespace alb-sample-app
& 해당 namespace 로 fargate 프로파일도 작성
2. nginx Application, NLB 생성
로드밸런서의 타입인 Instance 와 IP 중 Fargate 는 IP 타겟만 지정 가능하다. Instance 는 node 로, IP 는 pod 로 라우팅된다. 아래 스크립트는 선택기가 app=nginx 인 pod 로 라우팅하는 ALB 를 생성한다.
$ kubectl apply -f sample.yaml
Deployment/sample-app created
Service/sample-service-nodeport created
Ingress/sample-ingress created
3. 서비스 확인
$ kubectl get svc sample-service-nodeport -n alb-sample-app
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sample-service-nodeport NodePort 172.20.23.108 <none> 80:31517/TCP 4s
$ kubectl get ingress sample-ingress -n alb-sample-app
NAME CLASS HOSTS ADDRESS PORTS AGE
sample-ingress <none> * k8s-samplein-1234d81632-1363801234.ap-northeast-2.elb.amazonaws.com 80 3h43m
여기까지 진행하였으면, AWS 관리콘솔에서 [로드밸런서] 와 [대상 그룹] 이 정상적으로 구동되었는지 확인한다.
로드밸런서 : DNS 이름 / application 유형 / internet-facing 체계
대상그룹 : 80 port / HTTP protocal / IP target / Health status
4. 결과 확인
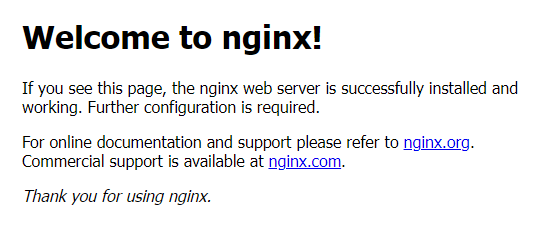
상단 ingress DNS 주소로 curl 이나 browser 를 사용하여 nginx 첫 페이지를 확인한다.